Lessons of Running Cursor Cloud Agents
If you haven't used one: a Cursor Cloud agent is Cursor running on a branch of your repo, somewhere that isn't your laptop. You send it a task, it makes changes, pushes a branch, and optionally opens a PR. You can trigger one from the Cursor UI, a Slack command, or any HTTPS call. Most importantly, the work happens detached from whatever you're doing.
This is what I wish someone had told me when I started wiring them into my team's workflows 🙂
Start with something impressive small
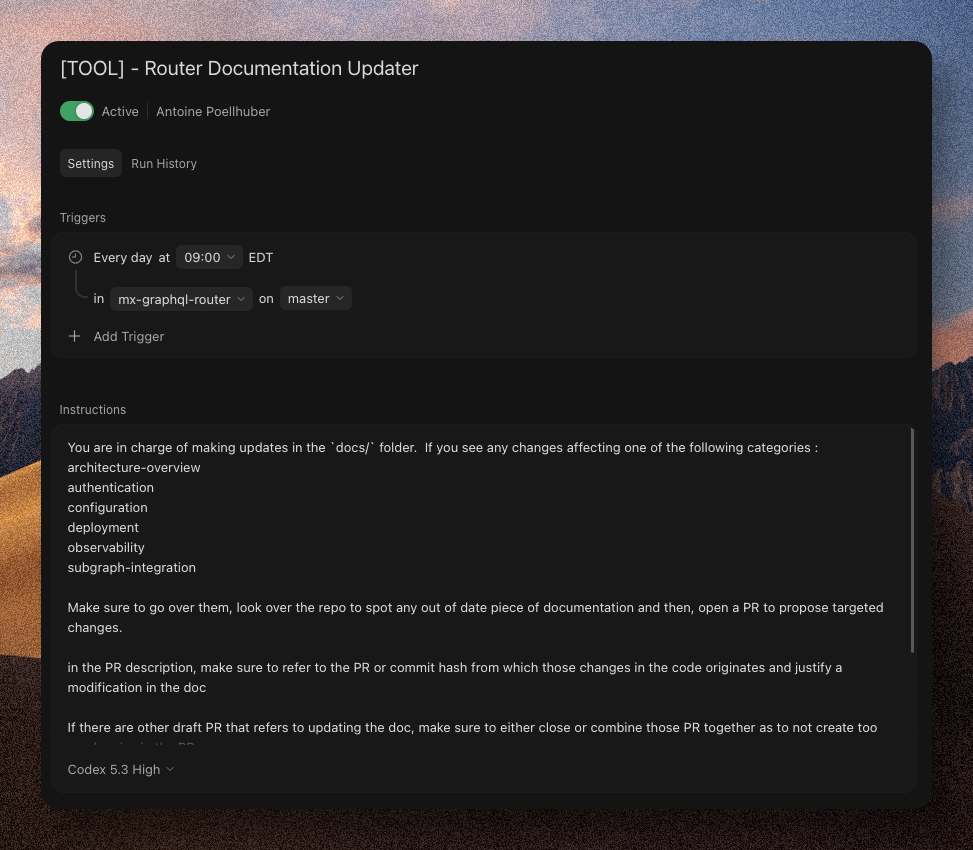
My first Cursor cloud agent was a documentation updater. Not a production bug fixer. Not a PR reviewer. A bot that checked whether a doc needed a refresh when a PR merged, and if so, opened a follow-up PR with the changes.
The task was dull. It wasn't on anyone's roadmap. That's why it was the right place to start: clear success criteria (does the doc match the code), small blast radius (the worst a bad PR can do is waste someone's time), and targeted scope (one file, one section).
Automations have a way of getting pitched as transformative. The documentation updater could misfire 3 times in a row and the blast radius was a stale paragraph that nobody would read. That's the setting where I figured out what Cloud Agents were actually good at — and their actual capacity, like checking for other draft PRs before trying to open one.
Side note: if I were building this automation today, I'd probably let Bugbot cover this use case. It wasn't rolled out yet when I built mine.
Keep the task surgical. Write "surgical" in the prompt.
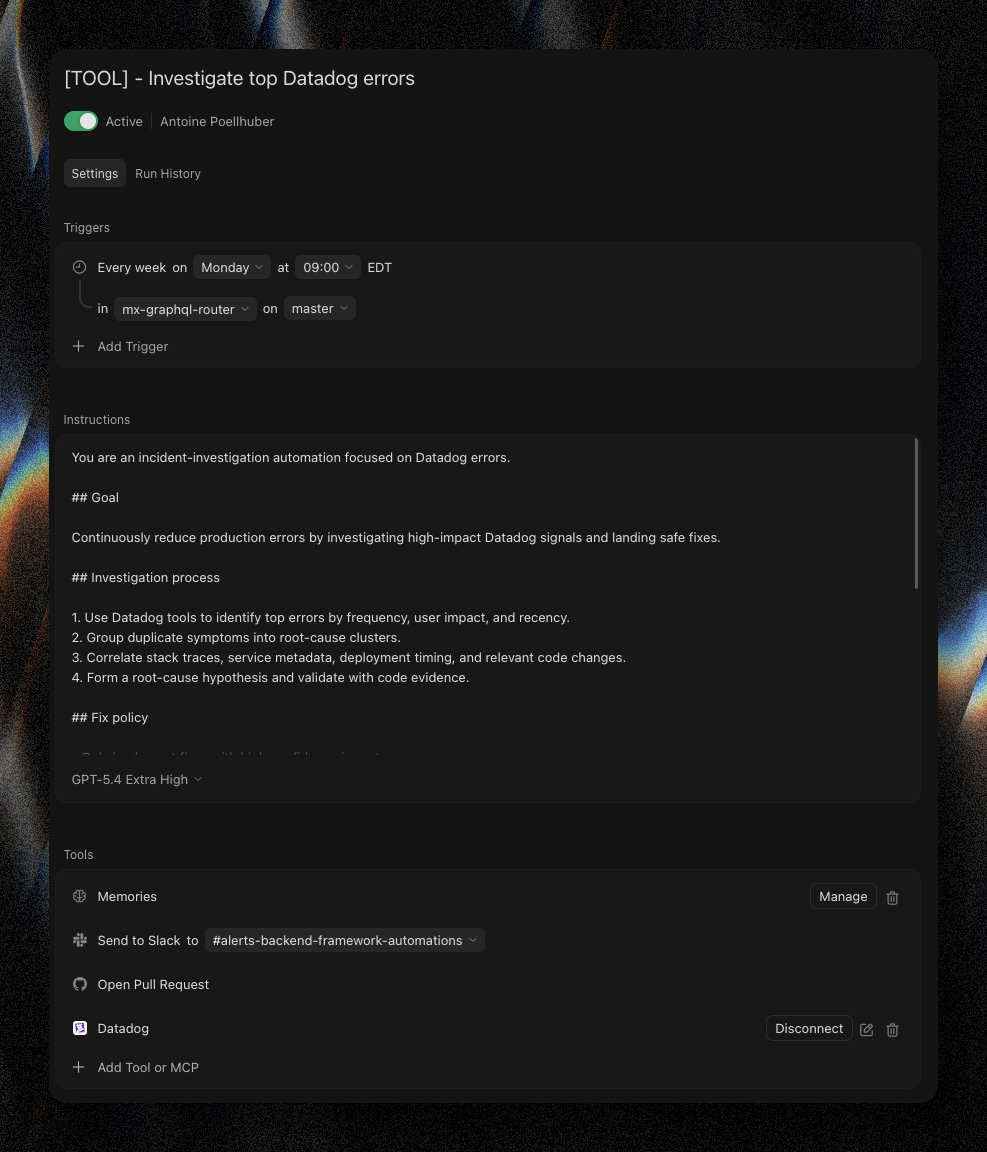
The second automation was a production-error bot. DataDog MCP wired to an agent that, every Monday, pulls the past week's errors, proposes a low-impact fix with an explanation, and posts the result to a dedicated Slack channel.
The single hardest constraint to enforce: only short, surgical fixes. No refactors. No architectural changes. No "while we're here, let's also clean up this other thing."
Agents love to spiral. If you let them, they'll try to fix the bug, then "improve" the surrounding code, then rename things for consistency, and you end up with a 40-file PR nobody wants to review.
Write "surgical fix only" in the prompt. Be aggressive about it. If you can scope to a single file or a single function, do that. The agent can absolutely do the big thing. You just don't want it to.
The docs bot broke the same way early on. Its original brief was "keep the docs consistent with the codebase," which is nightmarishly unbounded. Real changes were landing across multiple in-flight PRs, so the agent's updates kept going stale the moment another PR merged. The fix was: serialize, scope tighter, make the job be "this file, this section" instead of "make things consistent."
Agents behave better when their task is small and local. Humans too.
Give the agent a real container, not just a prompt
For any non-trivial task, the agent needs tools. It needs to run tests, read related files, query GitHub for context, maybe hit an internal API. The default Cursor environment doesn't have your stack, doesn't have your credentials, and doesn't know what "our deploy config" means.
For the error-fix bot I set up a dedicated Dockerfile with our project tooling baked in, plus a scoped GitHub token so the agent could call the GitHub MCP (related PRs, previous changes to the file, who owned the code). Before that, every fix was missing context — the agent was guessing from a stack trace and a code search. After, fix quality went up noticeably.
One thing the docs aren't so clear about: the agent will look for .cursor/Dockerfile, but also for a .devcontainer config if you have one. I'm currently migrating to .devcontainer because the spec is more standard and provides more tools. It's also a great investment since it lets new devs quickly onboard on a repo.
The half hour it takes to build a proper image for your agent is the best 30 minutes you'll spend on any of this. If you haven't already, check out containers.dev and the Cursor environment resolution docs.
Respect the review cost
Some of our first automations ran daily, mostly the error-fix automation. We dialed it back within a couple of days because we just couldn't keep up with the PRs. Each one needed real human eyes asking "is this actually the right fix?" Agent confidence does not equal correctness, and a fix that looks right but doesn't address the root cause wastes more time than it saves.
You are not saving reviewer time with agent automation. You are trading one kind of review for another. The new kind is often easier (smaller PRs, clearer intent), but it is not free — and if you fire automations at your team faster than they can process them, you'll end up resenting the bot and turning it off.
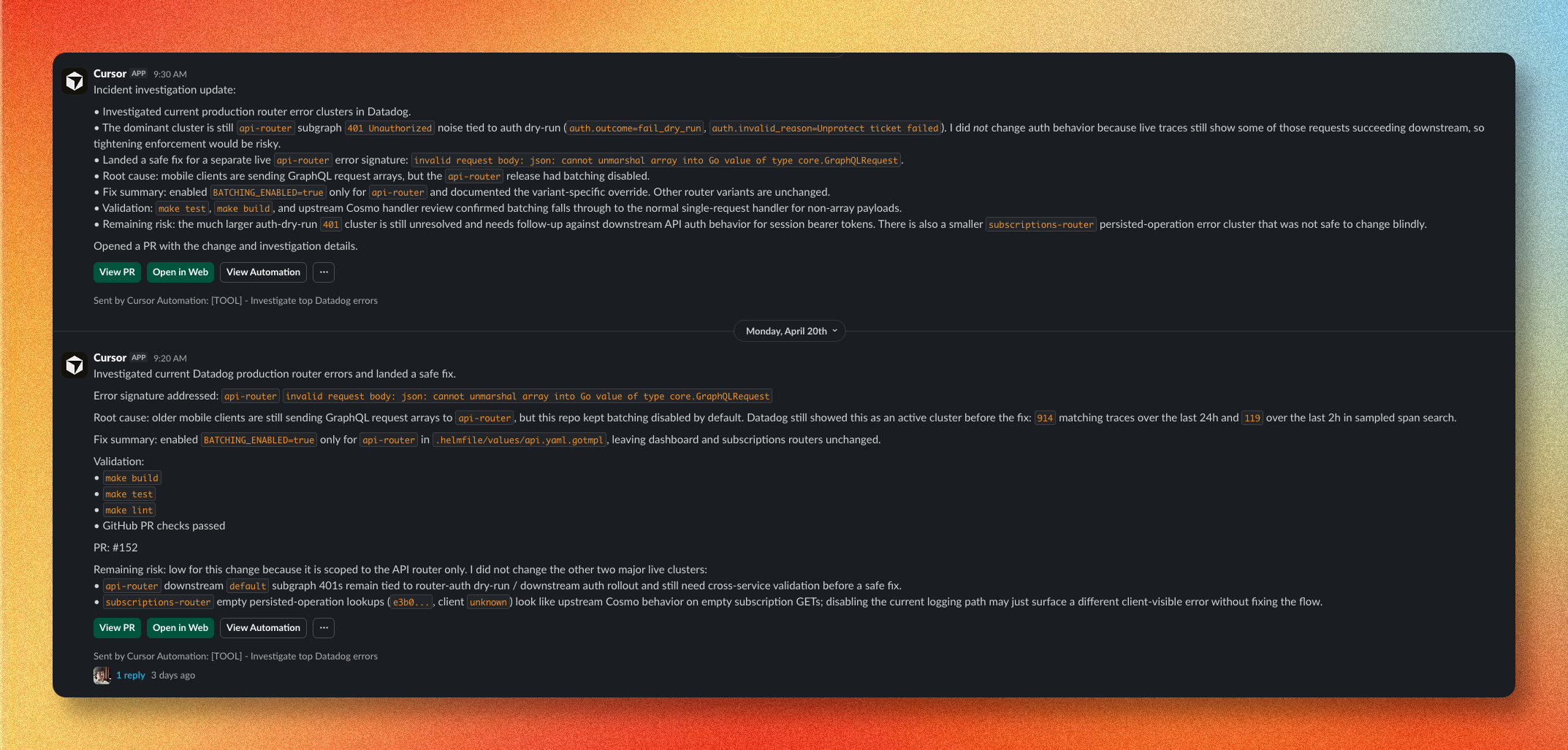
One thing that helps: put agent outputs in their own Slack channel. Not your alerts channel. Not your general notifications channel. A dedicated space, so the signal doesn't drown in noise that already has attention fatigue on it.
Master the triggers
Slack, cron, and GitHub webhooks cover most of what you need. For the gaps, GitHub Apps are genuinely underused and are the industry standard for letting third-party apps integrate with GitHub.

A GitHub App is a small backend service that can hook into any GitHub event, authenticate as a first-class GitHub entity, and call out to whatever system you want. They're not hard to build, well-documented, and let you wire a Cursor cloud agent into basically any workflow that touches your repo. If you need a trigger with custom filtering logic, a small GitHub App is probably the right answer — you can always let your Cursor Cloud Agents do the filtering, but that incurs cost and latency.
Know where the limit is
The DataDog loop resolves which service an error belongs to by referencing our deploy config. That got a lot easier once we had our Helm releases in a dedicated repo with clear service mappings. Another story for another time.
Our GraphQL router is a good candidate for cloud agent work: a small Go service, well-tested, containerized from day one. The agent can pull the repo, install deps, run it, test it — all without friction. The task fits in the box the agent runs in.
On the other hand, our main monorepo takes several minutes to clone, has quirks around in-code dependencies, and isn't containerized the same way. The moment you imagine pointing a cloud agent at it, the operational and technical limits show up immediately. That's why I've started looking into self-hosted cloud agents.
If you're running agent automations on production code and have done something smarter than any of the above, I'd like to hear about it — especially around the review-cost problem. I don't have a great answer for that one yet 🙂